|
There are a host of problems associated with using null hypothesis significance testing (NHST) to make binary decisions about whether research results are true or false (see the ASA statement and references therein (Wasserstein and Lazar 2016). Here we set most of those aside to focus on Type I error rates - specifically, we aim to show that Type I errors are probably more common than we’d all like to think... Recall that a Type I error is when the null hypothesis is “rejected” but was in fact true - in other words, a false positive. Most of us were taught that we choose the significance level (α) for an individual significance test in order to guard against having too many Type I errors. In fact the most commonly used α (0.05, meaning that we only “reject the null” erroneously 5% of the time) is directly the result of Neyman and Pearson trying to control errors in the long run. Whenever α is set, it anticipates a certain probability of a Type 1 error in each test. These probabilities accumulate across multiple individual tests so that the more significance tests one preforms, the greater the overall probability of at least one Type I error becomes. In contexts where many significance tests are going to be run researchers account for this problem by modifying α so that the “family-wise” error rate is more acceptable (e.g., the Bonferroni Correction). However, over a researcher may not make such a family-wise correction over the course of their entire career - especially since you don’t know in grad school how many significance tests you will perform during the rest of your life. This means that as a researcher performs more tests the probability that one or more of them will be a Type I error increases. Hopefully none of this is news. What may be new, though, is what happens when we try to quantify the probability of making a Type I error. The Probability of At Least One Type I Error Describing the probability of making a Type I error feels trivial, but it’s a bit more nuanced than you might think. At first glance it appears this is a simple case of adding the probabilities together (since you could get a Type I error on the first test OR the second test OR the third test…). That looks like: P(A or B) = P(A) + P(B) So for total Type I error rates across a bunch of NHSTs we could just take α as the probability of a Type I error on each test and multiply by the number of tests so that: P(Type I Error) = α × N where N is the number of tests. Not so fast! Unfortunately, this only works if the probabilities are mutually exclusive (both A and B can’t happen at the same time). Which we know isn’t the case since we could, of course, make a Type I error on more than one test. We can quickly see that this won’t work by assuming that N = 21 and α = 0.05 so that: P(Type I Error) = α × N = 0.05 × 21 = 1.05 But we know this can’t be right because probabilities must be bounded between 0 and 1. The problem is that we haven’t properly used the addition rule which reminds us to not double count the shared probability between the outcomes (e.g., the probability of more than one test resulting in a Type I error). What we should have used was: P(A or B) = P(A) + P(B) - P(A and B) So now we just need to know the value of P(A and B)… but we don’t actually know that. To get around this problem we need to get a bit more creative. We’re going to use complementary probabilities to get around the fact that we don’t know the joint probability(ies) of multiple independent Type I errors. This type of work around is often showcased using the “Birthday Paradox” which calculates (with some assumptions) the probability of at least one shared birthday between any two members of a group of a given size. (Amazingly it only takes a group of 23 people for the probability of a shared birthday to be 0.5). In our situation we are asking about the probability of at least one Type I error in N independent significance tests. For notational simplicity, let’s call that probability: P(R). We also know that the probability of zero Type I errors (call that P(R′)) is just the complement of P(R): P(R′) = 1 − P(R) It will be much easier to calculate the probability of no Type I errors across multiple tests because in this case we can use the multiplication rule since in order to have no Type I errors on multiple tests we must have no error on the first AND no error on the second AND on the third and so on. We know that we have used α as the probability of a Type I error on a given test, leaving us with: P(R′) = (1 − α1) × (1 − α2) × … (1 − αN) We’ll further assume that we use the same α in each test (which is common practise). This, then, further simplifies to: P(R′) = (1 − alpha)N That all gets us the probability of exactly zero Type I errors across N number of tests. But we wanted the probability of at least one Type I error across those N tests. The complement rule comes to our rescue again since that probability is simply the complement of the probability of no errors: P(R) = 1 − P(R′) And we can substitute the equation we just derived for P(R′) above and we get: P(R) = 1 −((1 − alpha)N) So let’s use this with our initial example where N = 21 and α = 0.05: P(R) = 1 − ((1 − 0.05)21) = 1 − (0.3405616) ≈ 0.66 Expected Number of Type 1 Errors Let’s say we want to think about this problem a little differently. Let’s now consider how many Type I errors we should expect in a given set of NHSTs. It turns out we already saw the solution to this at the top in our first attempt to calculate the probability of a Type I error. The expected value of a binomial distribution (which is what we get when we use NHST to generate a true/false outcome) is: E[x] = n × p Or, in our case: E[x]=N×α Let’s again use our example of α = 0.05 and N = 21. E[x] = N × α = 21 × 0.05 = 1.05 In other words, in 21 NHSTs we should expect, on average, 1.05 Type I errors. This reflects very common thinking about Type I errors, we should expect an error about every 20 significance tests - this is true. But it considers this expectation as a single value. When we consider the expected number of tests to an error as a random variable that can be described as a probability distribution, the problem gets more complex. The Probability Distribution of the Number of Tests Before and Error We’ll now think probabilistically about how many trials a researcher should expect to run before encountering their first Type I error - this is a little different than just the average expectation in a given set. It turns out that we can use what’s called the geometric distribution for this - it tells us probability distribution of “success” on trial k in a given number of Bernoulli trials. It says that: P(X = k) = (1 − p) k−1p Where X = k means that success occurs on the kth trial. (Note that for our purposes we’re calling “success” a Type I error (ironic as that may be) so that p = α. Hopefully you can see that this is basically the same thing that we calculated before. The expected number of trials up to and including the first success for the geometric distribution is just: E[X] = 1/p = 1/α = 1/0.05 = 20 Which is another way to say that we should expected, on average, to have to do 20 significance tests before getting our first Type 1. Not much new here. But now let’s look at it distributionally to see how much any instance might deviate from that expectation. 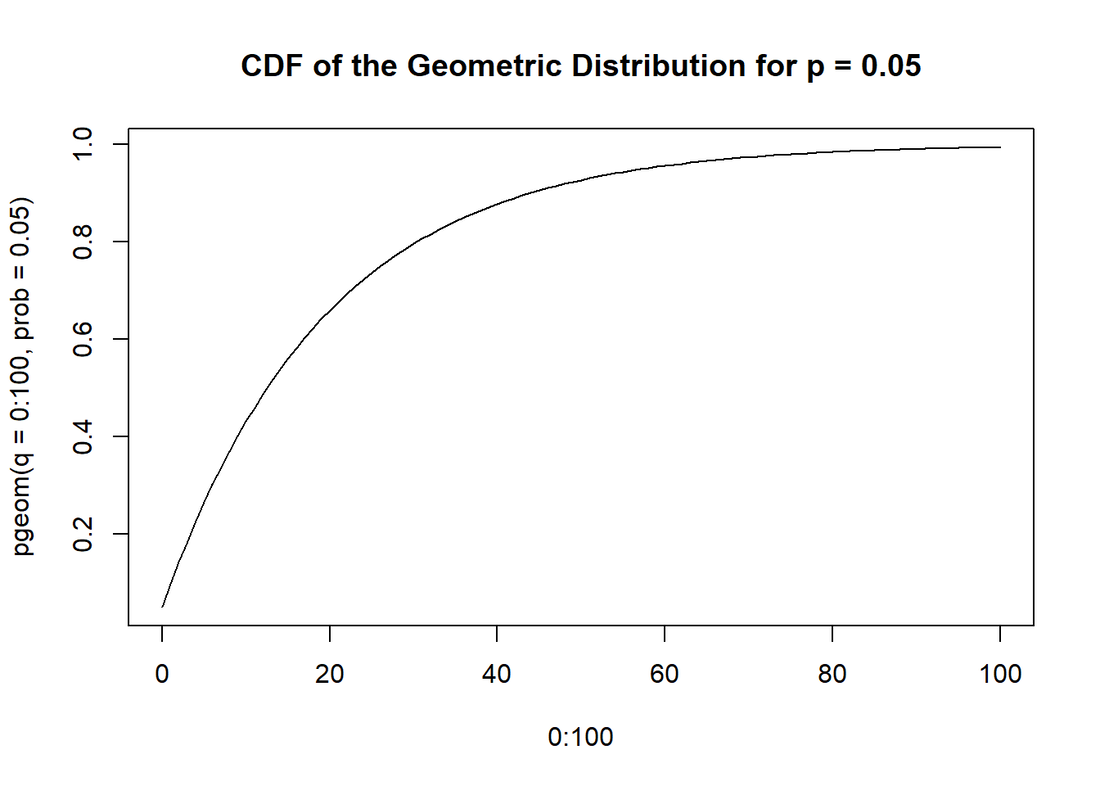 The cumulative distribution function plot shows us the number of tests on the x-axis and the cumulative probability on the y-axis. The first thing to note is that while the expected value of the geometric distribution for α = 0.05 may be 20, the probability of getting a Type I error for in fewer than 20 significance test is certainly not zero.
We can use the quantiles of the distribution to characterize this a few different ways. First, we can ask for the value of X (number of tests) that corresponds to a given quantile (probability of a Type I error). For example, the number of trials until the first Type I error for the lower half of the probability distribution is 13. Meaning that half of researchers will get a Type I error in 13 trials or fewer. This is far fewer than the intuitive E[X]=20. That’s should feel a little scary. We can also use the probability distribution to ask basically the converse question: what is the quantile associated with a value of X; in other words, what is the probability of a researcher getting a Type I error in X trials? Let’s try: What’s the probability of getting a Type I error in your first trial? Remember, the expected number of trials to error is still 20 on average, but some will hit this error right off the bat - what’s that number? 0.0975. Almost 10% of researchers will experience a Type I error on their first trial. That might put α = 0.05 in a different perspective for many people. Conclusion As we stated at the top: there are plenty of reasons to be suspicious of NHST. Many of these reasons are even more compelling than the risk of a Type I error. That said, looking at Type I error rates probabilistically should give us pause - the chances of making a predictable Type I error with NHSTs are wildly high and we never know which of our tests represent that error… References Wasserstein, R. L., and N. A. Lazar (2016). The ASA’s Statement on p-Values: Context, Process, and Purpose. 70:129–133.
0 Comments
|
Scott YancoI'm an ecologist studying how life uses movement as an adaptation to spatiotemporal heterogeneity. I also spend a lot of time talking dogmatically about inferential approaches. ArchivesCategories |
 RSS Feed
RSS Feed